---
dataset_info:
features:
- name: url
dtype: string
- name: permalink
dtype: string
- name: comments
sequence: string
- name: num_comments
dtype: int64
- name: subreddit
dtype: string
- name: title
dtype: string
splits:
- name: train
num_bytes: 4997779774
num_examples: 590721
download_size: 3184699498
dataset_size: 4997779774
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: mit
---
# BLIFT: Behavior-LLaVA Instruction Fine-Tuning Dataset
Paper: [**Teaching Human Behavior Improves Content Understanding Abilities of VLMs**](https://openreview.net/forum?id=TrKq4Wlwcz)
Website: [https://behavior-in-the-wild.github.io/behavior-llava.html](https://behavior-in-the-wild.github.io/behavior-llava.html)
---
## Dataset Summary
**BLIFT** (Behavior-LLaVA Instruction Fine-Tuning) is a large-scale multimodal instruction tuning dataset designed to teach **Vision-Language Models (VLMs)** human behavior. It contains over **730k images and videos** collected from Reddit and YouTube, annotated with **reciever behavior** such as **comments, likes, views, and replay graphs**.
By modeling these downstream receiver behaviors, training on BLIFT improves **content understanding** of VLMs, showing significant improvements across 46 tasks in image, video, text, and audio understanding.
 ---
## Dataset Structure
Each sample in BLIFT includes:
| Field | Type | Description |
|------------------|-----------|-----------------------------------------------------------------------------|
| `permalink` | `string` | URL to the reddit post |
| `url` | `string` | Media URL |
| `title` | `string` | Title of the post or video |
| `comments` | `list[str]` | Top user comments (cleaned and filtered) |
| `num_comments` | `int` | Number of comments on the post |
| `subreddit` | `string` | Subreddit source |
---
## Data Sources
BLIFT combines high-quality behavioral data from two sources:
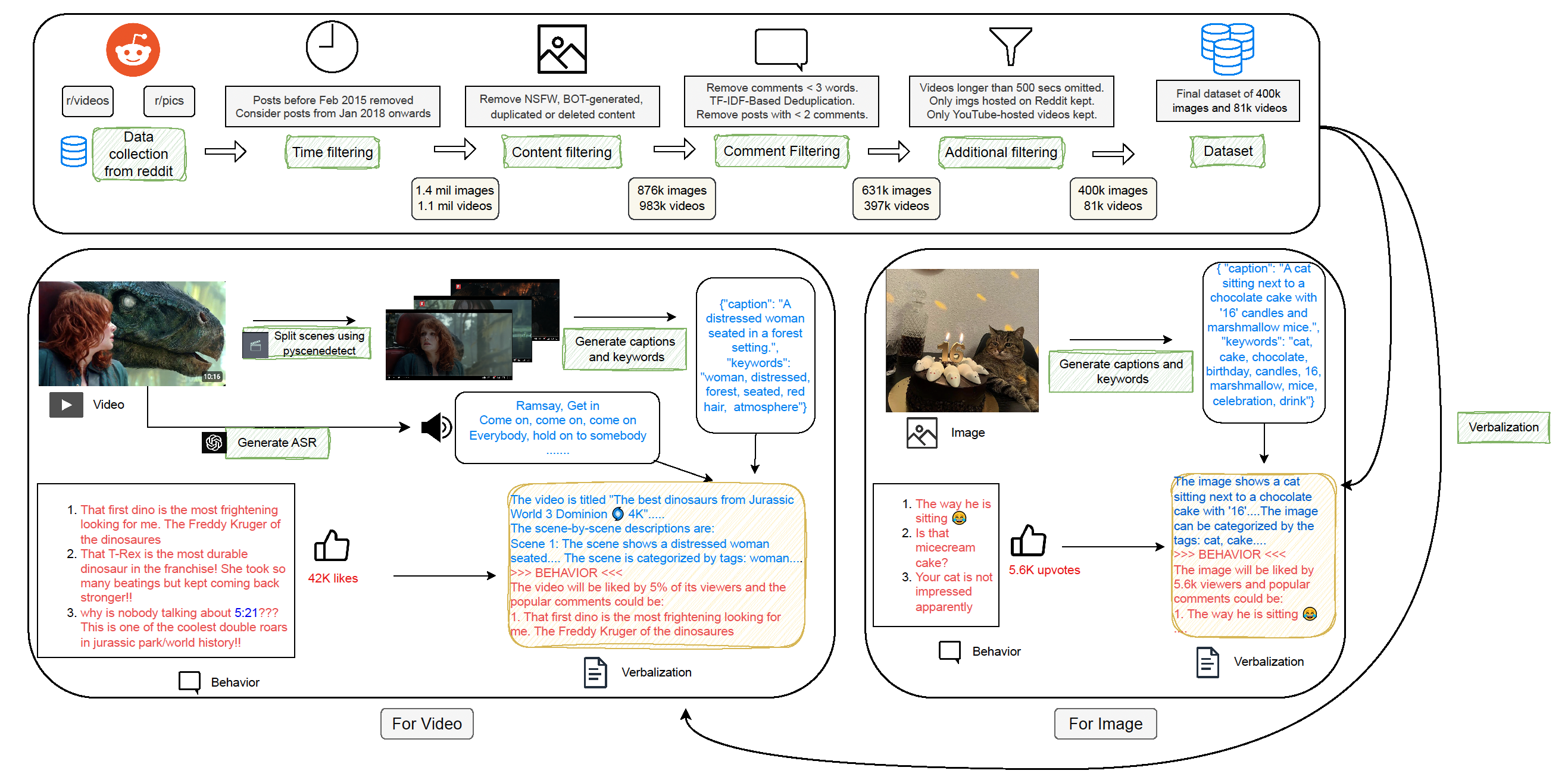
### Reddit
- Subreddits: `r/pics`, `r/videos`
- Collected: 400k images, 330k videos
- Metadata: Upvotes and top comments
- Filtering: NSFW, bots, duplicates, minimum comment quality
### YouTube
- 250k videos from ~6,000 verified channels via Wikidata
- Metadata: Likes, views, top comments, replay graphs
- Filtering: English language, minimum 10k views, NSFW, duplicates
---
## Dataset Structure
Each sample in BLIFT includes:
| Field | Type | Description |
|------------------|-----------|-----------------------------------------------------------------------------|
| `permalink` | `string` | URL to the reddit post |
| `url` | `string` | Media URL |
| `title` | `string` | Title of the post or video |
| `comments` | `list[str]` | Top user comments (cleaned and filtered) |
| `num_comments` | `int` | Number of comments on the post |
| `subreddit` | `string` | Subreddit source |
---
## Data Sources
BLIFT combines high-quality behavioral data from two sources:
### Reddit
- Subreddits: `r/pics`, `r/videos`
- Collected: 400k images, 330k videos
- Metadata: Upvotes and top comments
- Filtering: NSFW, bots, duplicates, minimum comment quality
### YouTube
- 250k videos from ~6,000 verified channels via Wikidata
- Metadata: Likes, views, top comments, replay graphs
- Filtering: English language, minimum 10k views, NSFW, duplicates
 ---
## Benchmarks & Results
Using BLIFT to train **Behavior-LLaVA** (a fine-tuned LLaMA-Vid), the model outperforms base LLaMA-Vid and other supervised baselines on:
- 46 tasks
- 26 benchmark datasets
- Across image, video, audio, and text modalities
---
## Benchmarks & Results
Using BLIFT to train **Behavior-LLaVA** (a fine-tuned LLaMA-Vid), the model outperforms base LLaMA-Vid and other supervised baselines on:
- 46 tasks
- 26 benchmark datasets
- Across image, video, audio, and text modalities
.png) ---
## 🔗 Citation
If you use BLIFT, please cite:
```bibtex
@article{singh2024teaching,
title={Teaching Human Behavior Improves Content Understanding Abilities Of LLMs},
author={Singh, Somesh and SI, Harini and Singla, Yaman K and Baths, Veeky and Shah, Rajiv Ratn and Chen, Changyou and Krishnamurthy, Balaji},
journal={arXiv preprint arXiv:2405.00942},
year={2024}
}
```
---
## Contact
Contact behavior-in-the-wild@googlegroups.com for questions and suggestions.
---
## 🔗 Citation
If you use BLIFT, please cite:
```bibtex
@article{singh2024teaching,
title={Teaching Human Behavior Improves Content Understanding Abilities Of LLMs},
author={Singh, Somesh and SI, Harini and Singla, Yaman K and Baths, Veeky and Shah, Rajiv Ratn and Chen, Changyou and Krishnamurthy, Balaji},
journal={arXiv preprint arXiv:2405.00942},
year={2024}
}
```
---
## Contact
Contact behavior-in-the-wild@googlegroups.com for questions and suggestions.